



The Problem
One of the major challenges faced by Dachser is accurately classifying multi-page documents that span various languages. Since they provide logistics solutions across borders they have to process numerous documents without a unified structure such as invoices, bills of lading, and certificates of origin. With documents arriving in unstructured formats such as PDFs, the automated solution must effectively classify and categorize these documents based on their content and context, regardless of the number of pages or the language used.
Furthermore, Dachser frequently receives collections of documents bundled together in a single PDF file. The challenge lies in extracting and separating these individual documents for further processing. The proposed solution must be capable of intelligently identifying and isolating different documents within a single PDF file, considering variations in document structure, formatting, and language.
Since this task required knowledge in natural language processing, data engineering and DevOps, Dachser decided to seek support from kreuzwerker to ensure a state-of-the-art implementation inside the AWS ecosystem.
The Solution
In order to address these challenges, Dachser required a scalable solution that leverages technologies such as optical character recognition (OCR) and natural language processing (NLP). This solution must efficiently process a large volume of unstructured documents, classify them accurately based on their content and language, and intelligently separate collections of documents within a single PDF file.
The initial step involved extracting text from a set of documents provided by Dachser using AWS Textract. In order to overcome the multi-language challenge, all the extracted text within the documents was translated into English with AWS Translate. This process ensured a standardized language for subsequent analysis and classification tasks.
Using the translated text, a training set was created to facilitate the training of a custom classifier model. The training set consisted of labeled examples, where each document was associated with a specific document type.
This training set was then submitted to the AWS Comprehend, which trained a custom classification model based on the labeled data. The trained custom classifier model was rigorously evaluated to assess its performance and effectiveness. Various evaluation metrics, such as accuracy, and F1 score, were computed to gauge the model’s ability to correctly classify documents. In the final step an inference pipeline was implemented, which can classify an input document using the trained model’s predictions.
The diagram below shows the complete architecture, which was designed with scalability and industry standards in mind.
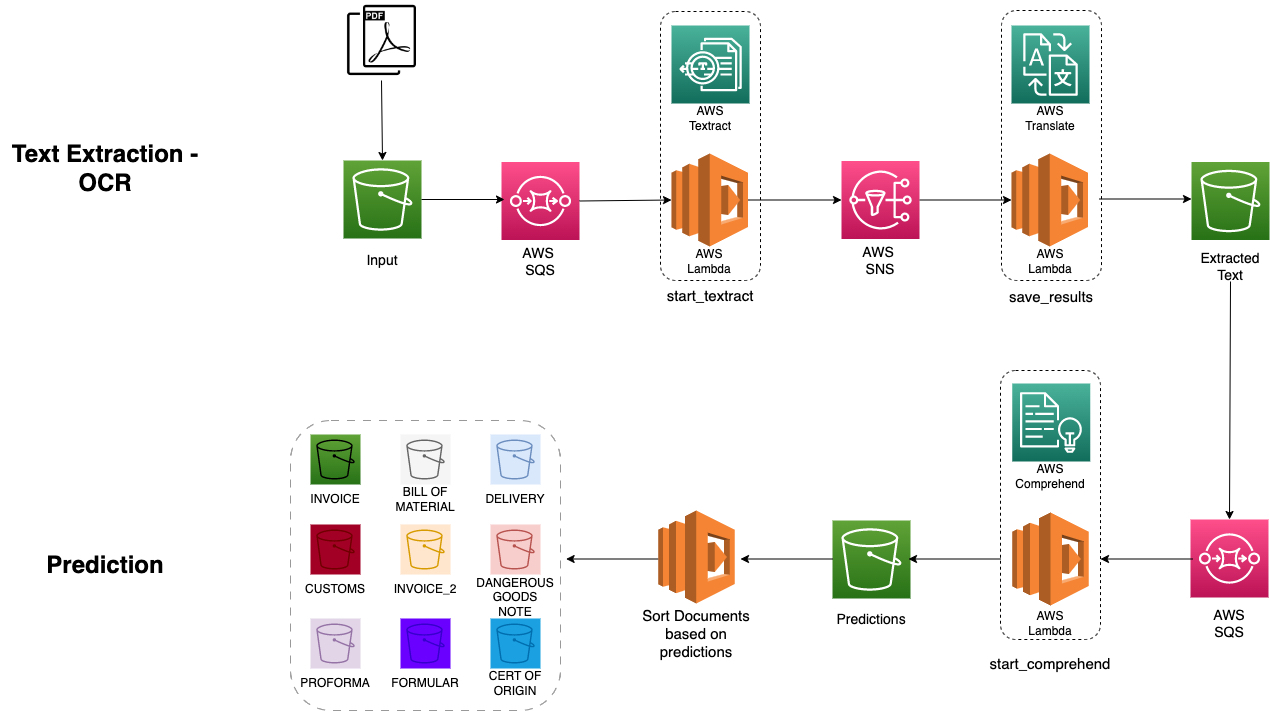
The Result
The designed solution could classify up to 1000 documents concurrently with an accuracy of 95%. In order to reduce complexity, development time and operational overhead, the entire solution was created using serverless services provided by AWS. This approach, along with the documentation, allowed an easily maintainable product and provided room for further improvement even without a dedicated team of machine learning experts.
Summary
Dachser, a global logistics provider, partnered with kreuzwerker and tested a scalable solution within the AWS ecosystem to streamline their document management processes. The solution utilized OCR and NLP technologies to accurately classify multi-page documents in various languages and extract individual documents from bundled PDF files. By leveraging AWS Textract for text extraction and AWS Comprehend for training a custom classification model, Dachser, with kreuzwerker’s support, was able to build up a state-of-the-art intelligent document processing solution in just a few weeks.