


How monitoring can improve the security and availability of systems
For customers, problems with the availability and security of their applications and infrastructures are a nuisance.
In this case study, we show how we at kreuzwerker use monitoring solutions such as Datadog to optimize the availability and data security of our customers - for greater customer satisfaction and a strong relationship between kreuzwerker and our customers.
Availability
Problem
One of our customer’s major vulnerabilities is facing potential downtimes caused by an EC2 instances or application availability problems, such as those stemming from DoS attacks.
A specific incident highlighting this vulnerability occurred in early October, precisely at 2:23 am on a Saturday. A Confluence outage took place, prompting the on-call kreuzwerker operator to take action.
Solution
To maintain a robust system, we have established an on-call schedule for our customer, providing round-the-clock support in the event of any incidents. We ensure continuous (24/7) monitoring of our infrastructure, specifically focusing on EC2 instance metrics such as CPU usage, disk usage, available RAM and other important metrics. This monitoring is supported through our dedicated monitoring tools, Datadog and New Relic.
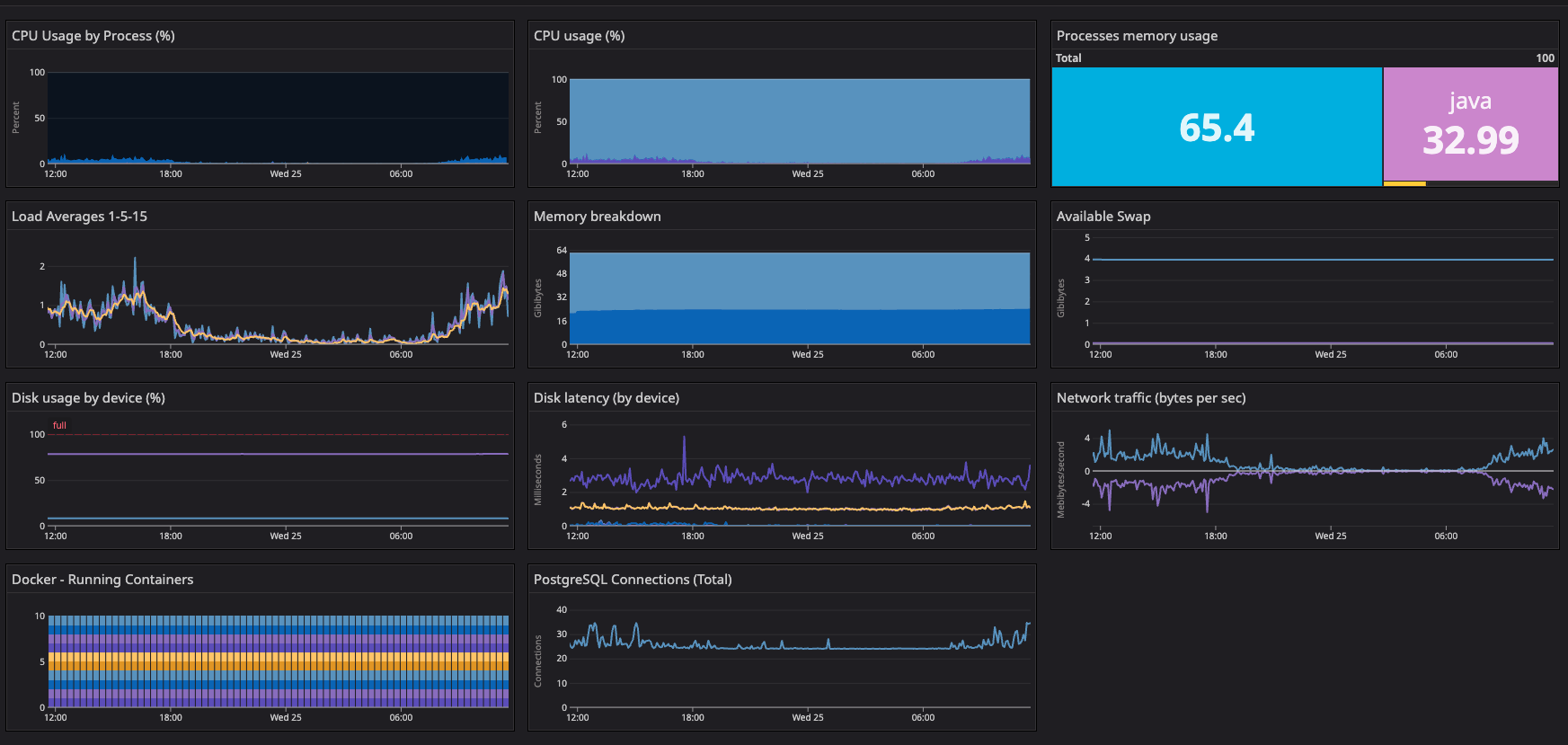
Furthermore, we closely monitor specific metrics related to the customer’s Atlassian Java applications, including swapping, garbage collection, and heap allocations. In the event of any issues, our Datadog monitors promptly trigger alerts, seamlessly integrated with our messaging platform Slack and operations tool OpsGenie. This integration ensures that the employee on-call promptly receives the necessary notifications, as can be seen below:
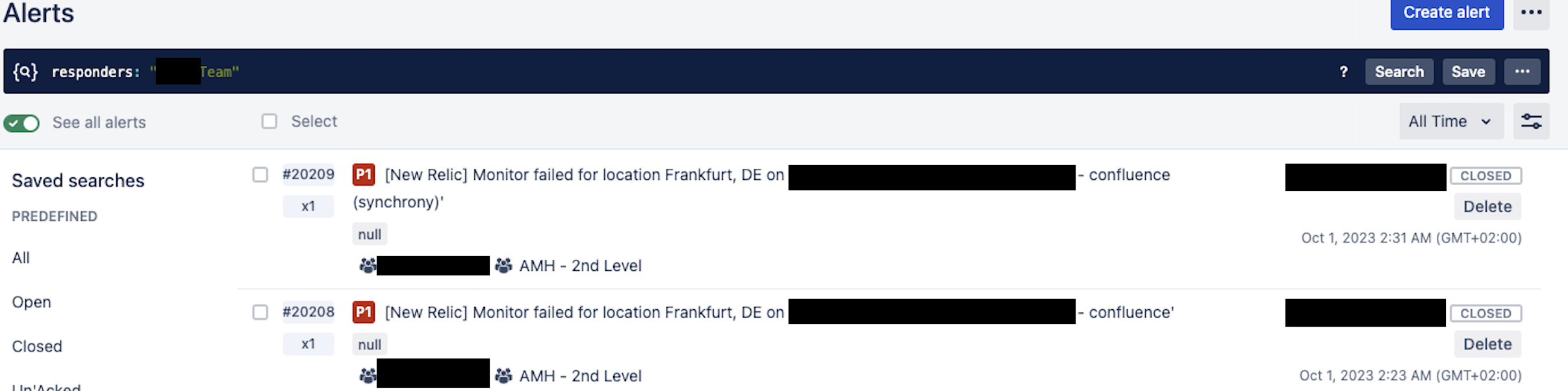
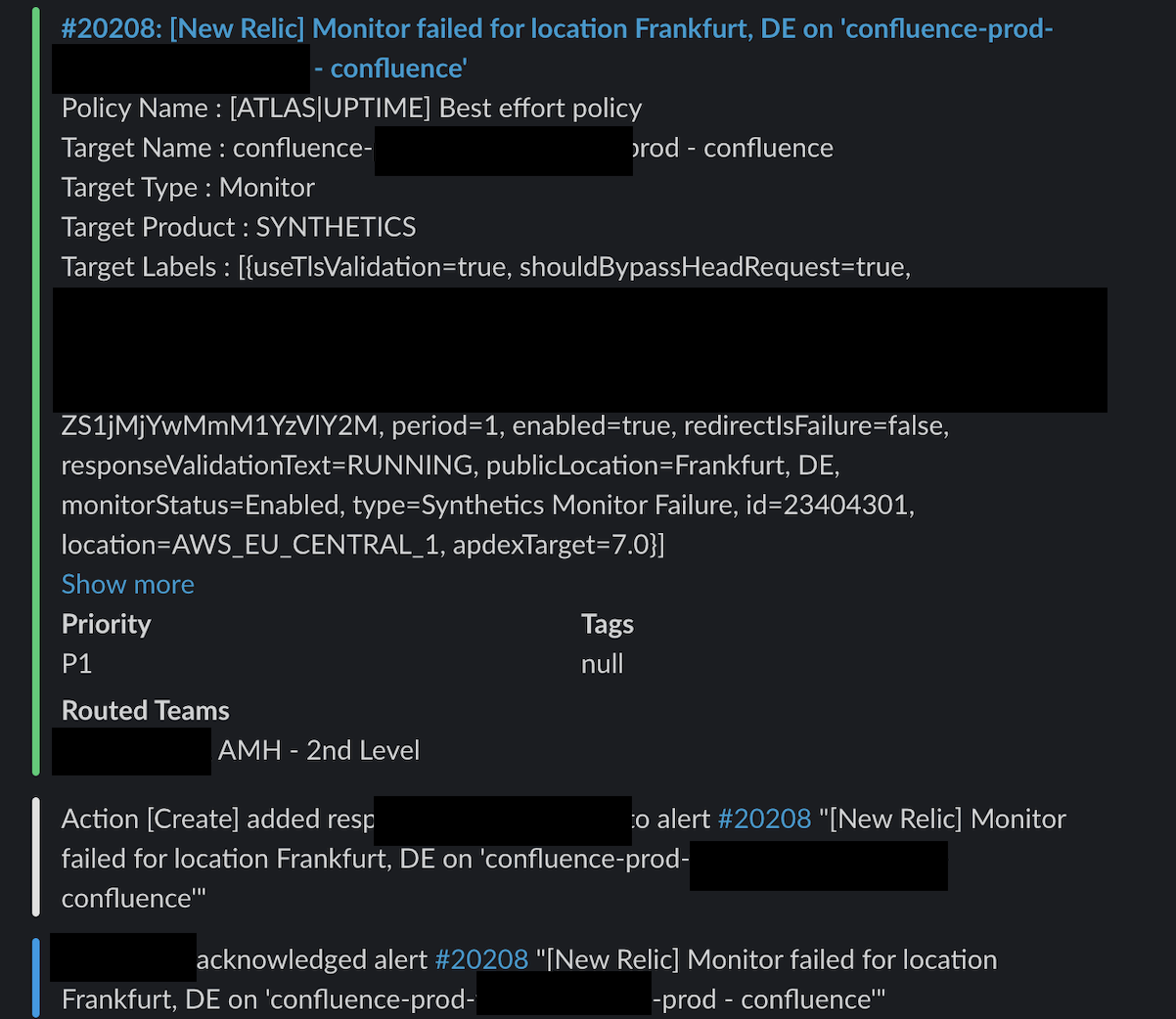
In case of the problem described above, a swift restart provided a temporary resolution, successfully bringing Confluence back to normal operation after 8 minutes. Ongoing monitoring revealed a continuous increase in CPU usage and load on the Confluence instance, which ultimately led to the outage. Upon detailed investigation of the logs, it was discovered that numerous requests from a user were triggering high-load tasks, notably PDF exports, through the proxy to Confluence:
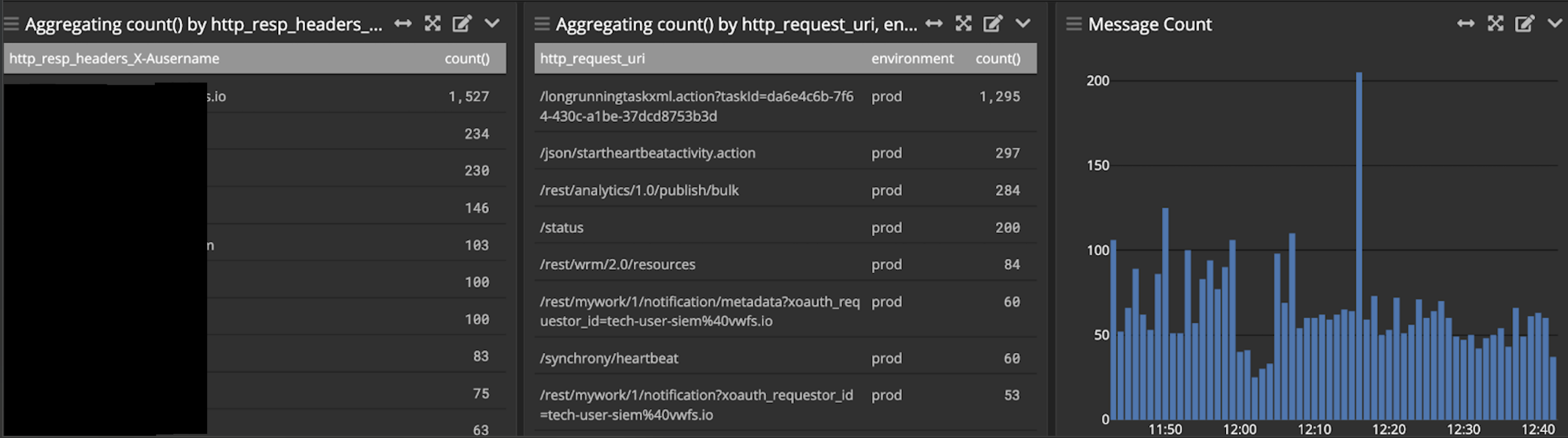
Despite notifying the user as well as the customer via email and a Service Desk ticket, the requests persisted several hours after the incident.
To prevent any additional outages, the user was subsequently blocked, which effectively resolved the performance issues.
Result
The customer subsequently endorsed our process, clarifying that the user’s requests were unintentional and automated.
The continuous monitoring of the customer’s infrastructure and applications around the clock therefore contributed to a consistently stable system, as evident from the subsequent uptime report:
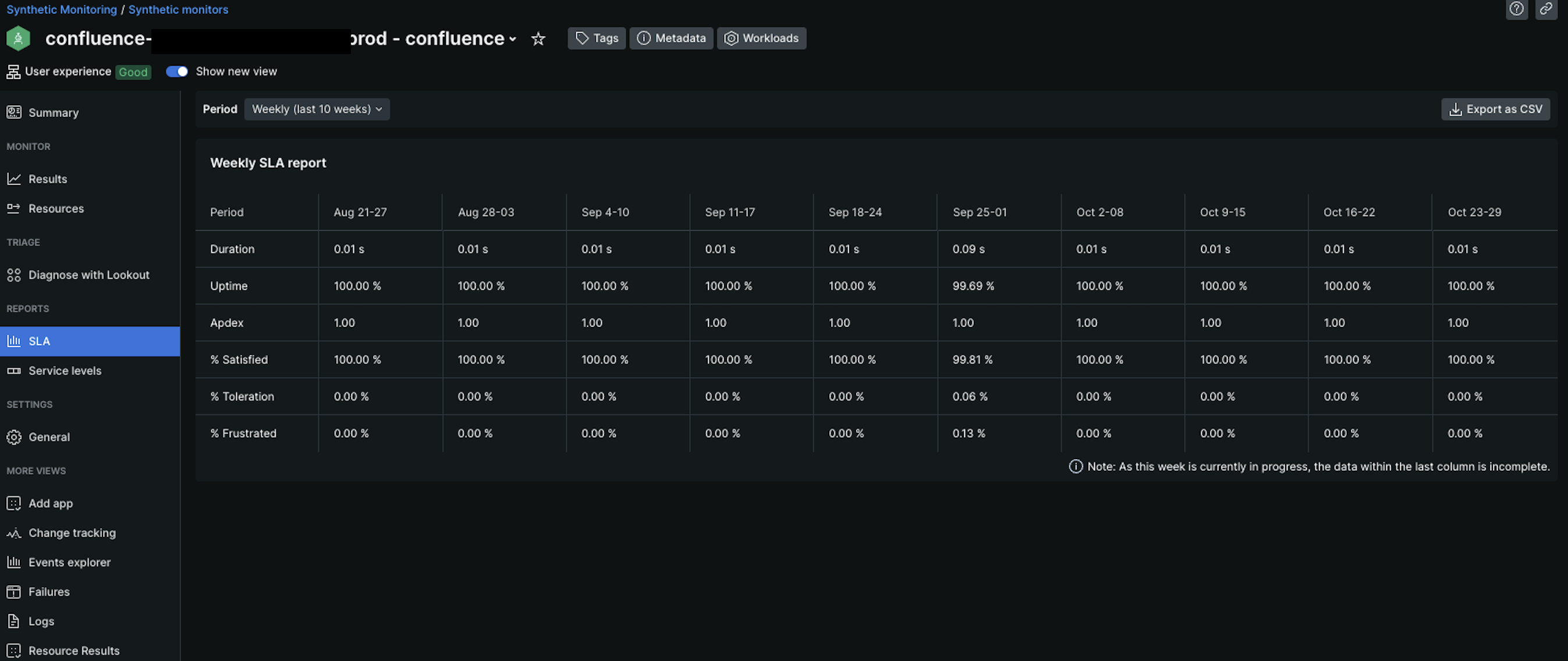
Security
Problem
The customer is also highly interested in security concerns surrounding vulnerabilities within Atlassian applications and the flatcar operating system. CVEs on either the application level or the OS might lead to security breaches.
In June 2022, the spotlight was on a critical security issue — a zero-day unauthenticated remote code execution (CVE-2022-26134) — in Atlassian Confluence (Server and Data Center) applications. This caught our attention, prompting swift action from our agile internal vulnerability management team, who closely monitors multiple channels for vulnerability alerts such as this one.
- https://confluence.atlassian.com/doc/confluence-security-advisory-2022-06-02-1130377146.html
- https://www.cert-bund.de/advisoryshort/CB-K22-0681
- https://jira.atlassian.com/browse/CONFSERVER-79016
Solution
Our team consistently monitors the flatcar operating system, as well as specific Atlassian application CVEs and promptly addresses any identified issues.
Security monitoring is managed by a range of resources, including announcements from Atlassian concerning application-specific CVEs.

Moreover, we use secalerts.co to receive information about CVEs affecting software we are using, such as flatcar. secalerts integrates with our Jira and Slack, generating tickets and alerts within our network.
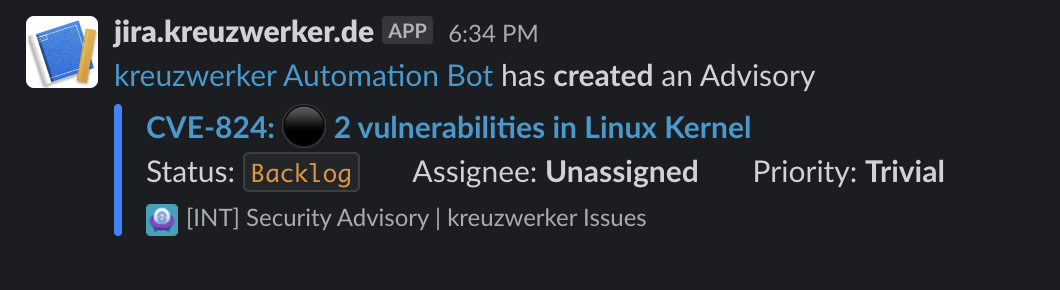
These alerts are carefully assessed, evaluating the potential impact on our customer. In situations of elevated risk, we proactively communicate to customers, providing detailed insights into specific issues, potential fixes, and available workarounds to mitigate risks where possible. For critical events, we sometimes conduct system patches during non-business hours, prioritizing the security of our customers’ systems, even in the absence of prior customer approval.
In addition to the two security monitoring solutions above, we use Amazon Inspector to scan our container images and the corresponding libraries for vulnerabilities:
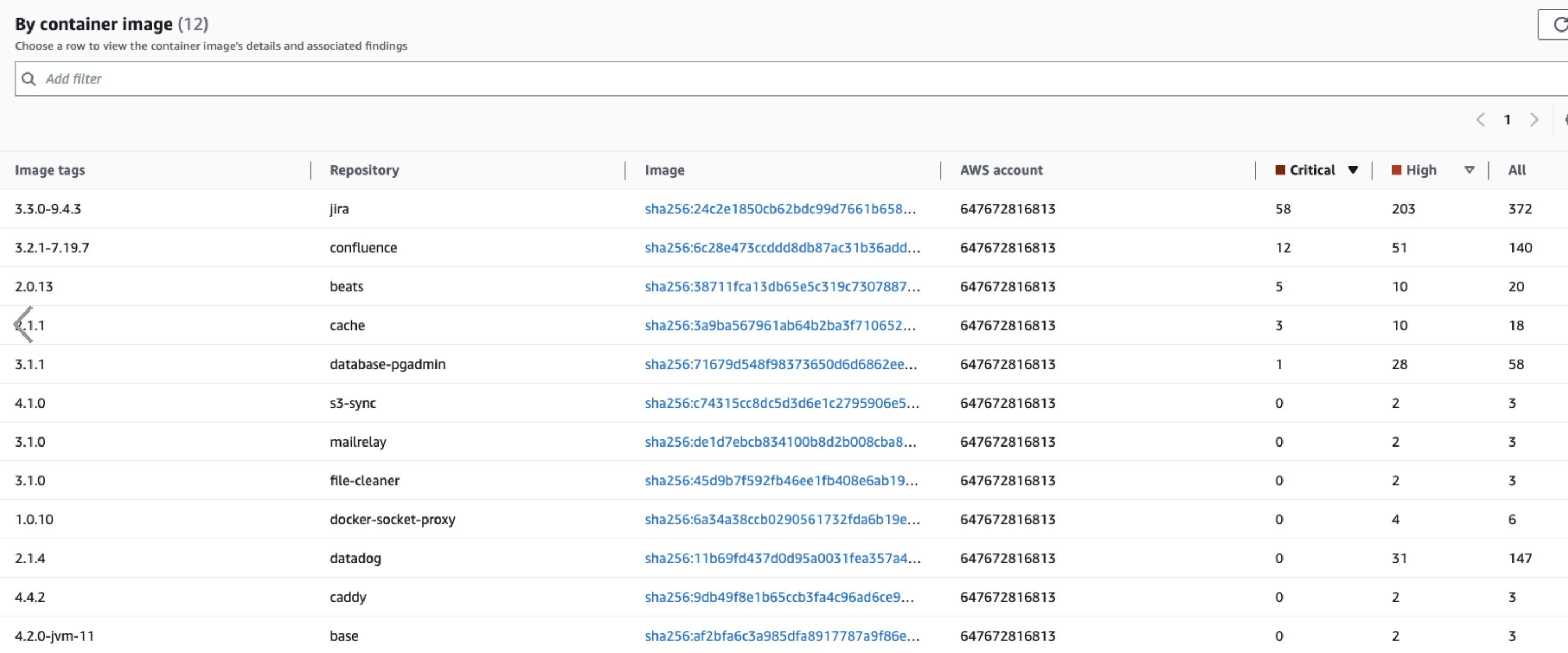
When fixable by us, we patch the libraries and deploy the patched containers asap. One example can be seen in the screenshot below, in which we fixed multiple critical and high findings in our PostgreSQL container:
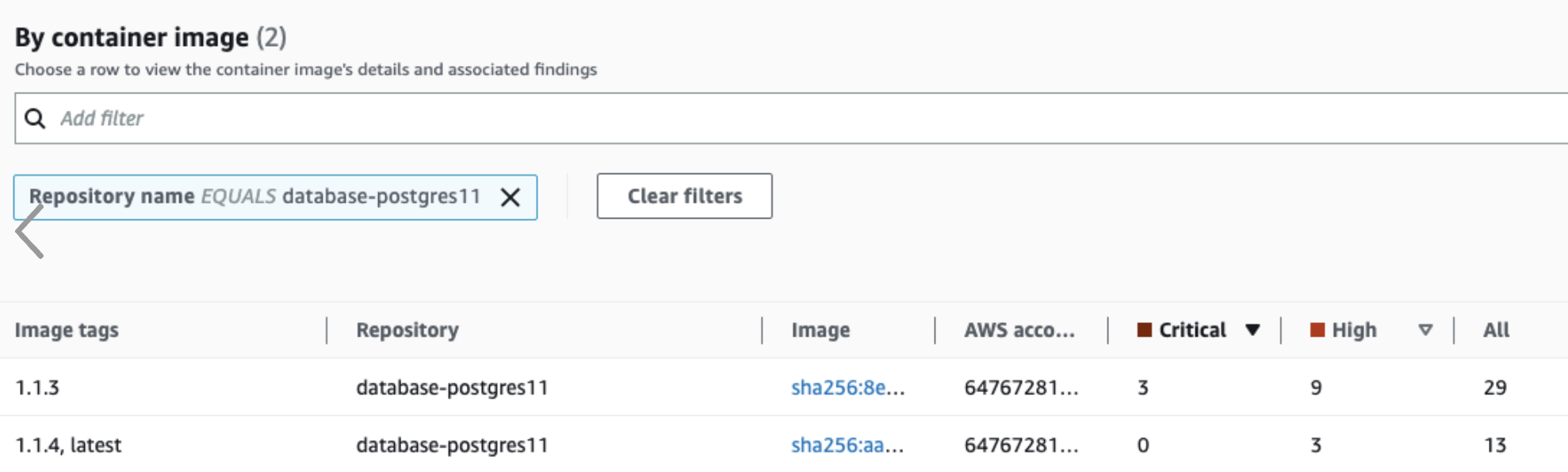
Regarding the previously mentioned incident, we quickly notified our customers’ technical contacts and implemented the recommended mitigations, including the blocking of requests that matched specific URL patterns. Furthermore, we enforced IP whitelisting to restrict access to instances where feasible. Once Atlassian released the patch version, we applied the automated deployment process, ensuring that the fix was seamlessly integrated into the customer’s system within a matter of hours.
Result
The above three security procedures therefore guarantee that the software running on the customer’s EC2 instances is patched and secure. This protects the customer data from potential exploits as well as possible.