

This blog post is part 2 in the series “Tips & Tricks for better log analysis with Kibana”. The other parts can be found here Part 1 and here Part 3.
This blog post is part of a series on making your life easier when using Kibana for log analysis. In the previous blog post I described why it’s important to define types for all known fields and suggested two approaches for dealing with unknown fields. In this article I will explain the two approaches in detail and discuss the pros and cons of each.
So let’s quickly recap the issue with unknown fields when using Elasticsearch’s default settings. Assume we have an application sending logs to Elasticsearch. If a log entry contains a new, previously unknown field, then Elasticsearch will automatically detect its type e.g. numeric and add the field to the mapping. From this point on, any other log entry that has a field with the same name but an incompatible type - e.g. boolean - will be rejected because of a mapping conflict. In the worst case, this can result in a lot of logs missing from Kibana - rendering the whole system basically useless.
To mitigate the risk of mapping conflicts caused by unknown fields, I recommend one of the following two approaches:
- Ignore unknown fields, just store them without making them searchable. Add them afterwards to the mapping with the correct type if needed.
- Store unknown fields as the type you expect to match most new fields. If this type does not match, change it afterwards.
But before we dive into the two options, a short interlude regarding index templates.
Interlude: Index Templates
As mentioned in the previous blog post, types are defined in the mapping. Because with log data you usually create new indices all the time (either time-based, e.g. daily, or size-based, e.g. when the size exceeds 10GB) it’s not sufficient to create one index with one mapping. Instead, you need to define an index template which contains the mapping that is applied to every new index. Thus, all the examples in this blog post will use the template API instead of the mapping API.
And just like in the previous blog post: all of the examples were done with Elasticsearch 6.7.0, using the logs sample dataset that comes with Kibana.
How to deal with unknown fields
Option #1: Ignore unknown fields
The first approach that helps in preventing mapping conflicts is to ignore all unknown fields in a document, so that no new fields will be added automatically to the mapping. Thus, no document can create a state where another document is incompatible.
This behavior can be achieved by setting the dynamic property to false on the top-level of the mapping type.
PUT /_template/access-logs-not-dynamic
{
"index_patterns": ["access-logs-not-dynamic*"],
"mappings": {
"_doc": {
"dynamic": false
}
}
}
The main drawback of this approach, however, is that new fields are not searchable until you have added them explicitly to the mapping. If you look at the fields from logs dataset in the Kibana Discover page, you can see that they are all marked with a question mark as shown below:
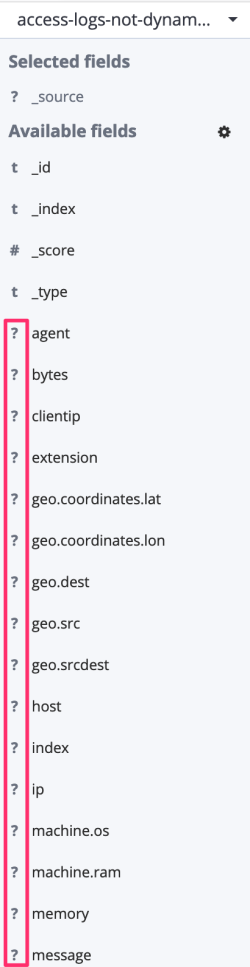
If you search for a specific value, e.g. for response code 200, no results will be shown:
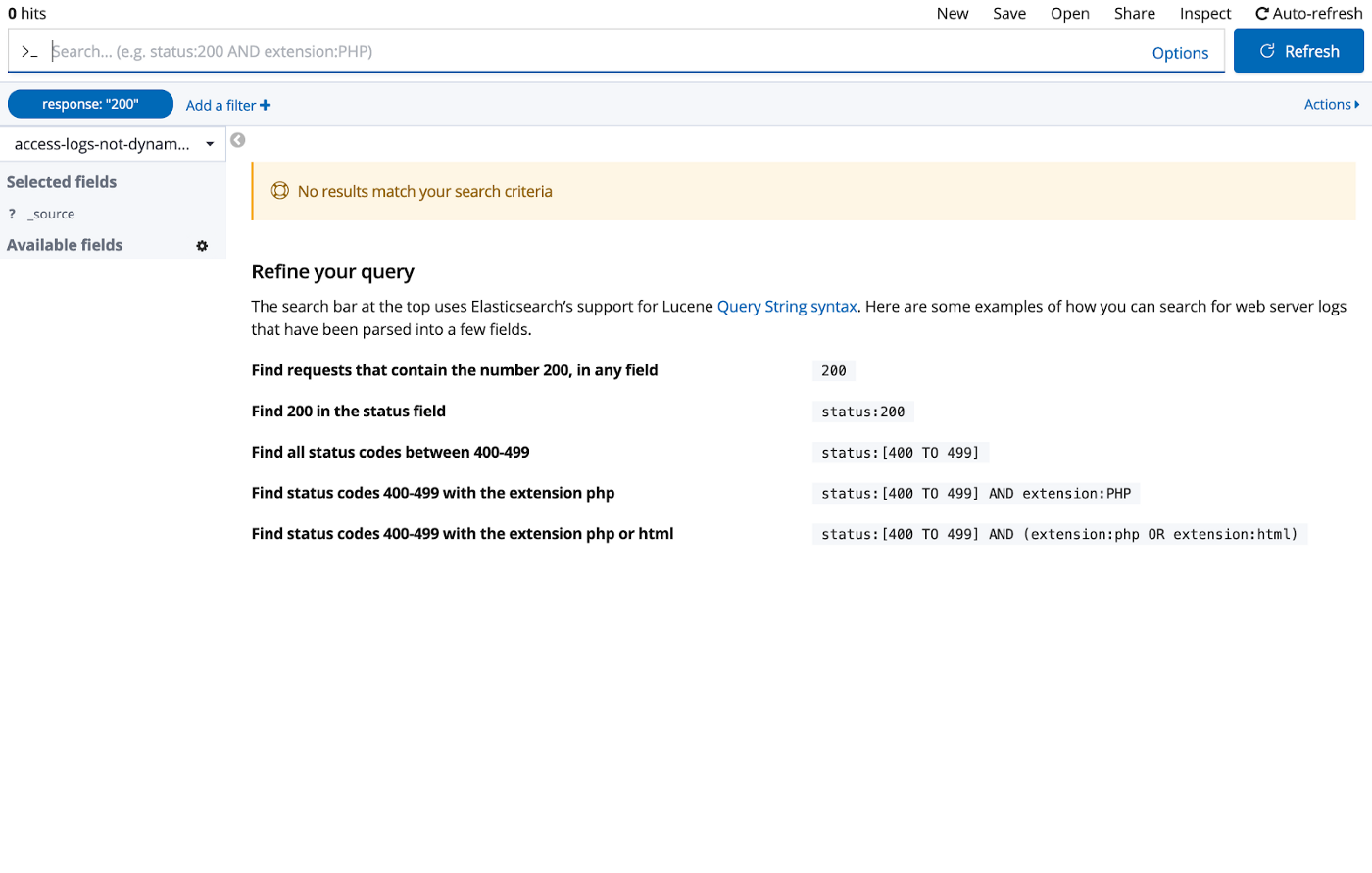
But as shown in the next image, the value is still included in the document. It’s just not searchable.
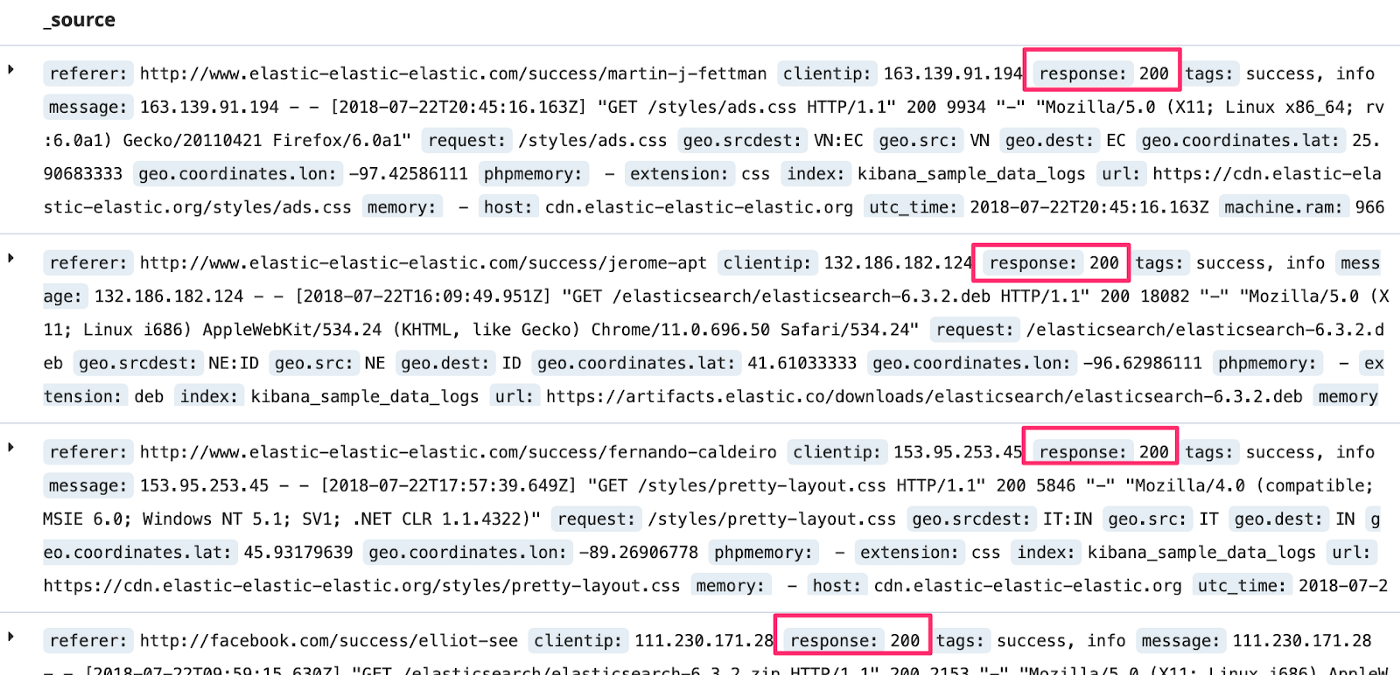
Option #2: Store everything as keyword
The second approach is to store all new fields as the type you expect to match most new fields. With log data I usually find the keyword datatype a good fit. It is (together with the other string datatype text) the most generic type, i.e. everything else except “object” can be mapped to it. I choose it over the text datatype since most fields in logs like logger name or log level don’t require a full-text search.
To enable this behavior you need to specify dynamic templates as shown below.
PUT /_template/access-logs-dynamic
{
"index_patterns": ["access-logs-dynamic*"],
"mappings": {
"_doc": {
"dynamic_templates": [
{
"object_as_object": {
"match_mapping_type": "object",
"mapping": {
"type": "object"
}
}
},
{
"everything_as_keywords": {
"match_mapping_type": "*",
"mapping": {
"type": "keyword"
}
}
}
]
}
}
}
The second entry defines that every type should be mapped as a keyword. Because JSON objects cannot be indexed as keyword, you need to add an additional template beforehand. This will exclude the object from the "match_mapping_type": "*" since templates are applied in order and the first matching one wins.
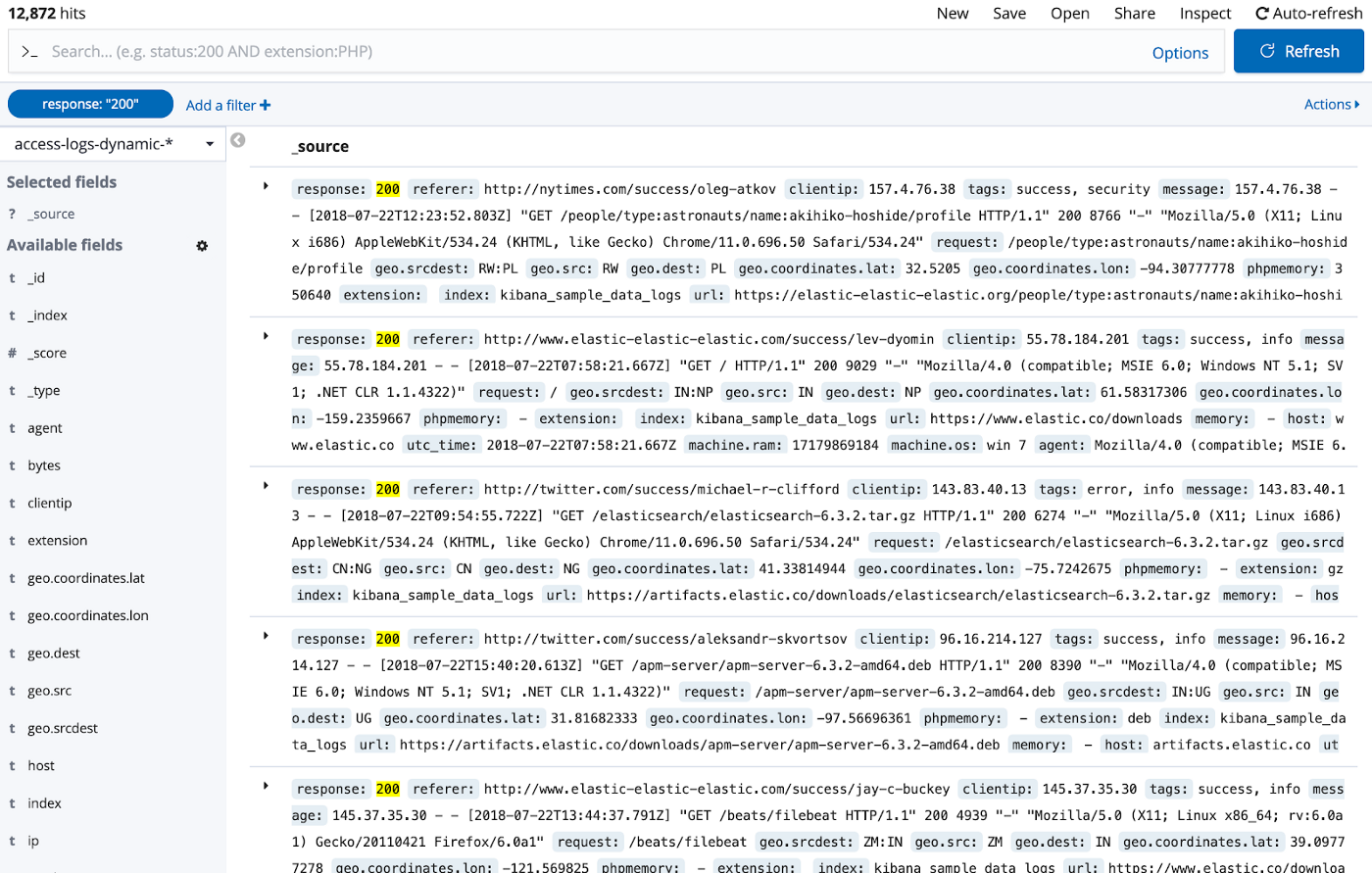
To see this behavior in action, I reindexed the logs dataset into another index. All fields in the Discover page are now marked with a t, meaning that they are strings:
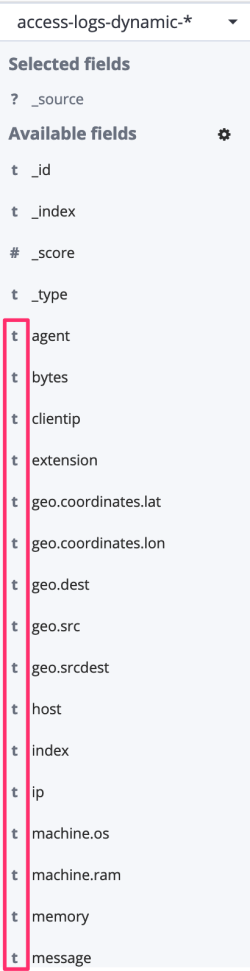
And when performing the same search as for Option #1, all documents with response code 200 are shown:
Comparison of the two options
So, is Option #2 always better because you can immediately search the fields? Maybe. Or maybe not if you recall the bytes example from the previous blog post. How often do you want to search for all requests with bytes=3218? Probably never. It’s more likely that you want to search for requests with bytes>0 or that you are interested in some distribution. The same will go for other numeric values. Even for the HTTP response code shown above, it would be much more useful to have the response code as a number. That way, you could filter out all 2xx requests by using response>=200 AND response <300.
If the type that is applied to new fields is not a good match in many cases, then you don’t gain much from Option #2. It’s actually a worse choice in that case since the process to change the type is more cumbersome.
Let’s assume we want to change the type of the response field to a number. Because Elasticsearch doesn’t allow you to update the mapping type of an existing field, you can only change it in the index template.1 Now we either have to wait until the index rolls over (e.g. because a new day started or our index reached a certain size) or we have to do a rollover manually. To make matters worse, Kibana won’t consider response a number until all old indices with the keyword mapping are gone. To solve this, you either need to create a new index pattern or reindex all existing data.
With Option #1, the field can easily be added to the mapping of the current index since it doesn’t exist yet. Thus, new log entries will instantly have the correct type and Kibana will be able to immediately treat it as a number as well.
A last thing to consider is how often new fields are actually added. If it does not happen often because you were able to define most fields upfront with their correct types, why bother with the more complicated dynamic templates? And even if fields are added, maybe they don’t even need to be searchable so you can save space and keep your mapping small by not indexing them.
To summarize: Use dynamic templates if new, searchable fields are added quite often and they mostly match the field definition applied by the dynamic template (Option #2). Otherwise, ignore new fields by default (Option #1).
No matter which approach you choose or even if you choose a hybrid-approach: It’s better than using the default behavior of dynamic field mapping since you will have deterministic behavior. Field types don’t accidentally change from one day to the next, and searches and visualizations that worked yesterday will still work today. Of course, it will very likely still happen that someone’s logs get rejected at some point, e.g. one team starts sending a user object even though the user field is already used to store the user id as a string. There is not much you can do about that except to educate everyone and have good monitoring in place.
Conclusion
I hope this and the previous blog posts have given you some ideas on how you can stabilize and improve your log analysis experience by:
- thinking beforehand about how your data is structured and what you want to do with your data,
- defining types accordingly, and
- implementing a strategy for dealing with unknown fields.
Stay tuned for the next blog post where I will show you some tips and tricks on how to improve performance and usability.
Credits for cover image go to: Unsplash
1 You could add a new multi-field to the existing field but that adds unnecessary complexity in the long term. ↩