

Introduction
In this blog post, I will share how I addressed a data synchronization challenge for a client by implementing an event-driven and serverless ETL (Extract, Transform and Load) solution.
Please note that this blog post focuses on the concepts and approach rather than providing code samples. However, it should give you a clear understanding of implementing ETL for your data workflow. If you require more advanced capabilities, consider exploring AWS Glue, which is beyond the scope of this blog.
Prerequisites and Assumptions
Before we proceed further, let’s establish some prerequisites and assumptions to ensure a smooth understanding of the content.
To fully grasp the concepts discussed in this blog post, it is beneficial to have a basic understanding of serverless architecture, ETL concepts, and familiarity with certain AWS services. Specifically, a working knowledge of Amazon API Gateway, Amazon EventBridge, and AWS Step Functions will be helpful. If you need a refresher or more information on these services, you can refer to the Technologies section under the appendix of this post, which provides a quick summary and links to external resources.
This blog post is written for readers who are either interested in leveraging AWS services to build an ETL-like solution or are simply curious to see how these services can be integrated and utilized to solve a real-world problem. Familiarity with Talend MDM and the target systems (CRM and ERP) is not mandatory to understand the concepts discussed here.
With the prerequisites and assumptions in mind, let’s now explore the problem at hand and delve into the solution implemented to address it.
Problem
My client has several products that they sell via a webshop. An external ERP (Enterprise Resource Planning) system manages the billing and finance-related actions. Another external CRM (Customer Relationship Management) system uses the product catalog and sales data to gather actionable insights. The product data in itself has a complex and hierarchical structure. Due to the constant research and addition of new products/hierarchies, this data requires a separate department and a specialized tool called Talend MDM (Master Data Management).
The entire catalog of products is updated and released in version-controlled iterations.
My client required an efficient method to synchronize this product master data (including name, description, category, and price) across different target systems (CRM, ERP and webshop). To achieve this, they needed a solution to extract master data from a specialized tool, Talend MDM (Master Data Management), and seamlessly transform and transmit it to the integration endpoints of the target systems.
Use case
Each product requires following steps:
- Extract relevant data from relevant Talend entities using Master Data Management (MDM) REST queries.
- Transform data into a single product entity with nested attributes by parsing, validating, and combining data from multiple entities.
- Load product data into different external systems, such as CRM and ERP by making REST calls to the respective target systems.
The ETL process is triggered manually when the container is ready to be synced, requiring simultaneous ETL operations for thousands of products.
As you can see, I’m basing this blog on an actual and somewhat specific use case. However, you can easily adapt the solution to satisfy your ETL needs.
Solution
The North Star
Below is a list of qualities our solution was expected to have and requirements that it had to fulfill. This list acted as the guide for designing the solution and selecting the right services.
- Low maintenance
- Simple to use and comprehend
- Covers error handling and retries
- Uses API endpoints for integration with external systems
- Transforms and syncs thousands of products in parallel for multiple targets
Workflow
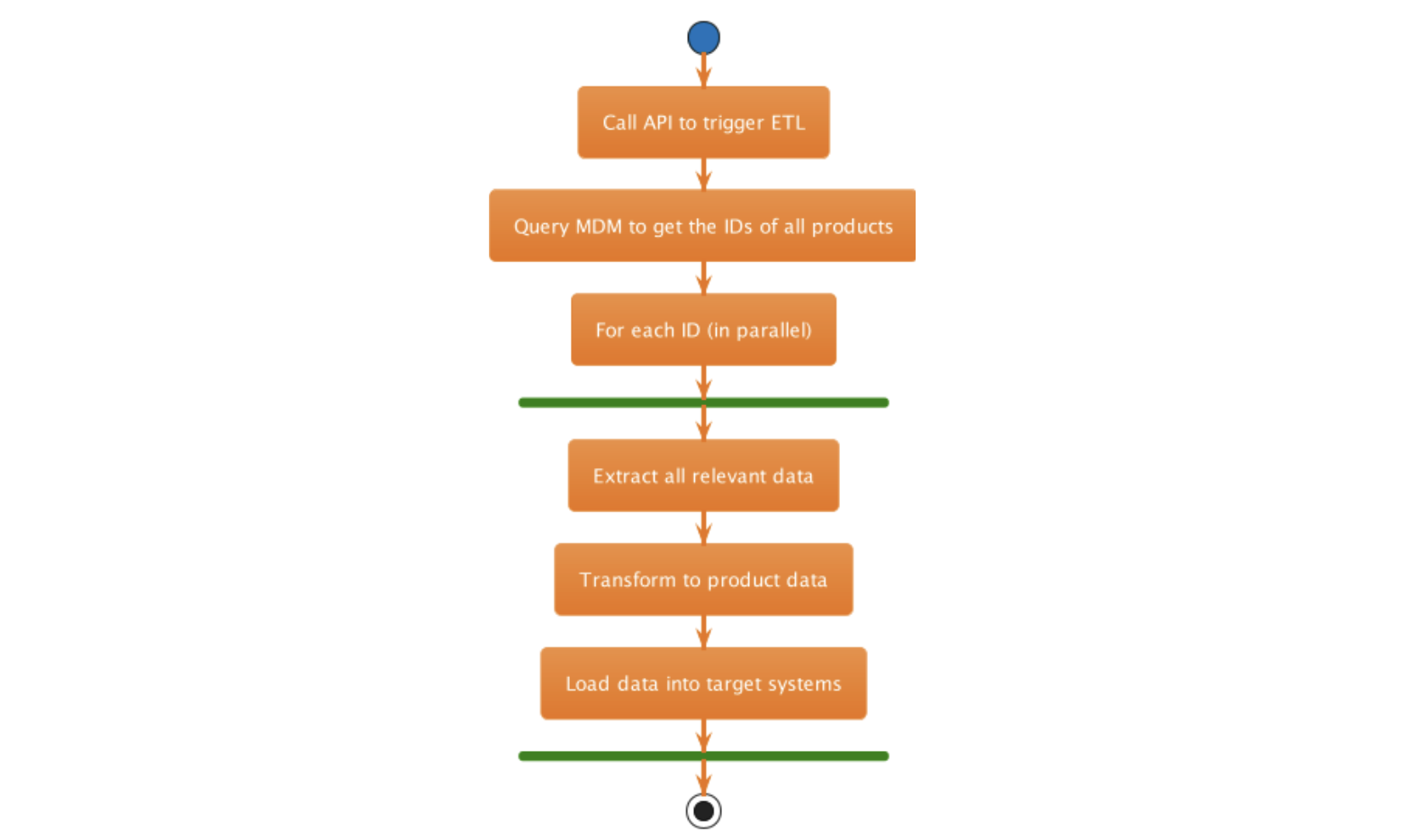
This solution exposes an API to trigger ETL. Once you call the API, it queries MDM to get the IDs of all existing products in the given container. The collection of IDs is then processed in parallel to extract and transform product data. After transformation, each product gets transferred to the target systems, in this case, CRM and ERP.
Architecture
Below is a high-level architecture diagram showing all the components of the solution.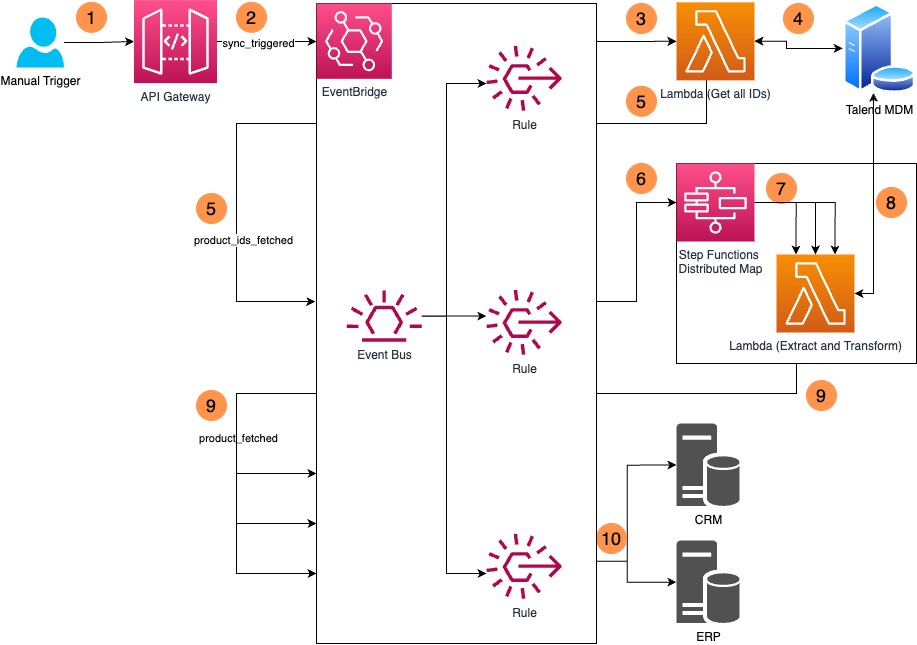
Detailed Steps
- Call an endpoint via REST to manually trigger the workflow.
- The API gateway verifies the authentication and puts a “sync_triggered” event to the event bus.
- A rule is evaluated and invokes a Lambda function.
- This Lambda function queries the IDs of all products from MDM.
- On successful execution, this Lambda function puts a “product_ids_fetched” event to the event bus containing a collection of all existing product IDs.
- Another rule is evaluated and invokes a step function, providing the collection of IDs as input.
- For each ID, a distributed map action invokes another Lambda function in parallel.
- This Lambda function extracts the data by making multiple select queries. It also transforms it into a product with desired nested attributes. (There was no need for me to separate the transformation from extraction. Based on your use case, you might have to separate it and even have different transformations for different targets)
- Once the product is extracted and transformed, the step function puts a “product_fetched” event to the event bus with the product data.
- A rule is evaluated and invokes 2 API destinations to transfer product data to CRM and ERP target applications.
Why use Amazon EventBridge?
You have the option to use only Step Functions for the entire workflow. Your API gateway can directly execute a state machine with states defined to carry out all three steps of ETL (Extract, Transform, and Load). If this approach aligns better with your use case, go for it. However, in my case, I chose to combine Step Functions with EventBridge for the following reasons:
Modular Workflow
Rather than having a single monolithic flow with multiple steps, using EventBridge allows me to break down the workflow into three smaller, modular flows: sync_triggered, product_ids_fetched, and product_fetched. This approach grants me the flexibility to trigger each flow individually by simply putting an event on the event bus. For instance, I can extract only a specific subset of products by putting a “product_ids_fetched” event with only the relevant product IDs. This way, I don’t have to trigger the complete container sync. This modularity becomes especially beneficial when dealing with failures. If the sync to target systems (CRM and ERP) fails, the event goes to a DLQ. After troubleshooting, I can easily replay the DLQ, which involves putting the failed events back into the event bus for re-syncing.
Flexibility and Extensibility
One of the advantages of using Amazon EventBridge is the ease of adding or removing targets for individual events. For example, I can configure the system to send email notifications to stakeholders (using Amazon SES) for every sync_triggered event or log the product IDs (in AWS CloudWatch) when the product_ids_fetched event occurs.
API Destinations
To synchronize products with CRM and ERP systems via REST calls, I utilized the “API destinations” feature of EventBridge. This functionality eliminates the need for writing additional code or relying on a Lambda function, making it straightforward to call target APIs directly.
Error Handling
Amazon EventBridge offers robust error-handling capabilities, including built-in retries, timeouts, and the option to attach Dead Letter Queues to each target. These features ensure that failed events are automatically retried and provide a mechanism for handling and reprocessing failed events.
Conclusion
In summary, by integrating Amazon EventBridge with Step Functions, I achieved a more modular and flexible ETL workflow. This combination allowed me to subdivide the process, easily manage targets for specific events, and improve error handling. The result was an effective solution for addressing the data synchronization requirements of this problem.
I hope this gives you a fair idea about how to streamline your data workflow and maybe even adapt this architecture to fit your use case.
Appendix
Technologies
In this section, I have provided a concise overview of the technical terms and services mentioned thus far in the article. Additionally, I have included links to external resources for those who wish to explore these topics in greater detail. If you know these already, skip this section and proceed to the next part.
ETL
ETL stands for Extract, Transform, Load. It is a process used to extract data from various sources, transform it into a suitable format, and load it into a target system.
Serverless
Serverless computing is a cloud computing model where you are not required to manage your application server (infrastructure). The cloud provider (like AWS) will manage the infrastructure and resources needed to execute your application and charge you only for the resources consumed during the execution of the application.
Amazon API Gateway
Amazon API Gateway allows you to create, publish, and manage APIs for your application. It’s, quite literally, the “gateway” to your application’s business logic and data.
Amazon EventBridge
Amazon EventBridge is a fully-managed event bus service that helps you create event-driven applications. EventBridge allows your application to integrate with AWS services and third-party SaaS applications.
Following are some crucial concepts concerning the EventBridge:
- Event Bus: A dynamic container that receives events from multiple sources and efficiently distributes them to designated targets, facilitating categorization and allowing for seamless event handling.
- Rules: A rule filters and routes the events of a specific event bus
- Targets: An event gets routed to one or more targets. These targets can be AWS services like Lambda functions, Step Functions, SQS, SNS, etc
- API Destination: API destination is a type of target that can send an event, or part of an event, to an HTTP endpoint.
- DLQ: Dead Letter Queue is a queue to hold the events that failed to be processed or transferred. Having a DLQ ensures you do not lose out on the “failed events” and allows you to troubleshoot or replay the events later.
AWS Step Functions
AWS Step Functions allow you to define and execute workflows by creating state machines and visualize these workflows with the help of a GUI. It also facilitates a distributed map that allows the parallel processing of multiple items in a collection.