

Introduction
This blog post is part of a series about the AWS Well-Architected Framework; what it is, why it makes sense to do it, and how we at kreuzwerker do it. In this entry, we will focus on the Operational Excellence Pillar.
What it is - a quick recap
Using the collective knowledge and experience of their architects and clients, AWS is continuously working on a Well-Architected Framework, which consists of key concepts, design principles, and best practices on how to architect and run workloads in the AWS Cloud. AWS developed a Well-Architected Framework in order to understand what makes some customers succeed in the cloud while others fail. They also wanted to identify common problems, decisional and architectural patterns as well as anti-patterns. In other words, what is well-architected and what is not, and to make this knowledge available to all, regardless of whether someone is only just considering migrating to the cloud, or is already running thousands of workloads there.
The Well-Architected Framework is built on six pillars
- operational excellence 👨🏽💻
- security 🔒
- reliability 💪🏾
- performance efficiency 🚀
- cost optimization 💵
- sustainability 🌳
The AWS Well-Architected Review process provides a consistent approach for customers and partners to evaluate architectures and implement scalable designs.
It’s important to note that the Well-Architected Review is not an audit. It’s nothing to be afraid of; there are no penalty points for not getting things right the first time. A Well-Architected Review is a way of working together on how to improve your architecture. The process leads through several foundational questions and checks. It has been derived from years of experience that have been gained from working with the AWS cloud regarding security, cost efficiency, and performance. Hence, it provides good advice on improvements. It helps you to build secure, high-performing, resilient, and efficient infrastructure for your applications and workloads.
The hard facts about AWS Well-Architected reviews in 2022 are:
- it consists of 58 questions in total across all pillars
- it takes around 4-6 hours for one workload (without tool support)
- the goal is to remediate 45% of the high-risk findings with a minimum of 20 questions answered.
We describe the process from our perspective in more detail here.
How we do it at kreuzwerker
Why should you do it with us?
As a Well-Architected partner, we do at least 20 well-architected reviews per year and have built overall deep architectural expertise for every pillar and hands-on experience.
How do we perform such a review?
For us, it’s an interactive process: we inspect and adapt every time we do it by requesting feedback from our clients and doing a short internal retrospective. As of now, we perform it as follows:
We do it in 2 blocks from 09:00-12:00 and 13:00-15:00 with a lunch break. However, we can continually adapt if we are faster, e.g., we shift the gap, and we are also flexible whether doing it remotely or at your office.
We do it in an interactive, story-telling mode. This means: you talk, we listen, and then dig deeper into specific areas while being able to cover multiple questions.
Our process is supported by tools (more in the other part of the blog post series 🥳)
We do not just handle the questioning but give guidance to answering them. We can tell you how and why there could be improvements to be made. Alright, enough for the introduction. Let’s jump right into it.
Operational Excellence Pillar
In a nutshell
This pillar outlines best practices to build architecture, which includes the ability to support development and run workloads effectively, to gain insights in their operations, and to improve continuously processes and procedures in order to deliver business value.
Design principles
- Perform operations as code
Of course, the best way to learn AWS is by using the AWS console and click through the input. But can you remember all the clicks and replicate these in another region? That would be manual work and you should always automate repetitive tasks. This design principle says that you should define your infrastructure to code. There are plenty of ways to write infrastructure as code (IaC). By IaC, you limit human error and enable consistent responses to events. - Make frequent, small, reversible changes
Imagine, your designer added a small animation which allows a better user experience but you don’t want to wait to the next release (which happens in 20 days) to deploy that. Or in a bigger scope, you promised your stakeholders that with next big release everything better and then the deployment went wrong. By making frequent, small and reversible changes, you would deploy faster and wouldn’t defend your team by the stakeholders for the failure. - Refine operations procedures frequently
Now, your app is running but you cannot rely on that everything works smoothly. Make sure to set up regular game days to review and validate that all procedures are effective and that teams are familiar with them. Furthermore, a bug found by a customer is a bit embarrassing and can cost some reputation. Therefore, it is always important as you evolve your workload to test it frequently. - Anticipate failure
Failures are good and you can only learn from them. Perform pre-mortem exercises to identify potential sources of failures. Combine that with a game day and let the team be familiar with all the procedures in case of a failure. - Learn from all operational failures
It’s also good to share and write post-mortem. Amazon, Netflix and many other big companies do that. These companies are not only sharing their success but also their failures and thus lessons learned to the public. Why? Because even big companies have outages and instead of fixing behind closed walls, they want to show that it happens to any company.
Improvement process
There are four best practice areas for operational excellence in the cloud.
Organization
Always keep in mind that there are many people involved and a shared understanding of your entire workload helps to set organization priorities that will enable business success.
Review your priorities regularly with external and internal stakeholders. Also evaluate governance and external compliance requirements. Use the AWS Cloud Compliance and AWS Trusted Advisor to educate your teams so that they can determine the impact on the priorities.
Understand your operating model because each team need to understand their roles in the success of other teams.
Below, you find a table of different operating model.
But before, here a list of abbreviations:
- Application Engineering and Operations (AEO)
- Infrastructure Engineering and Operations (IEO)
- Centralized Governance (CG)
| Model | Description | |
|---|---|---|
| Fully Seperated | 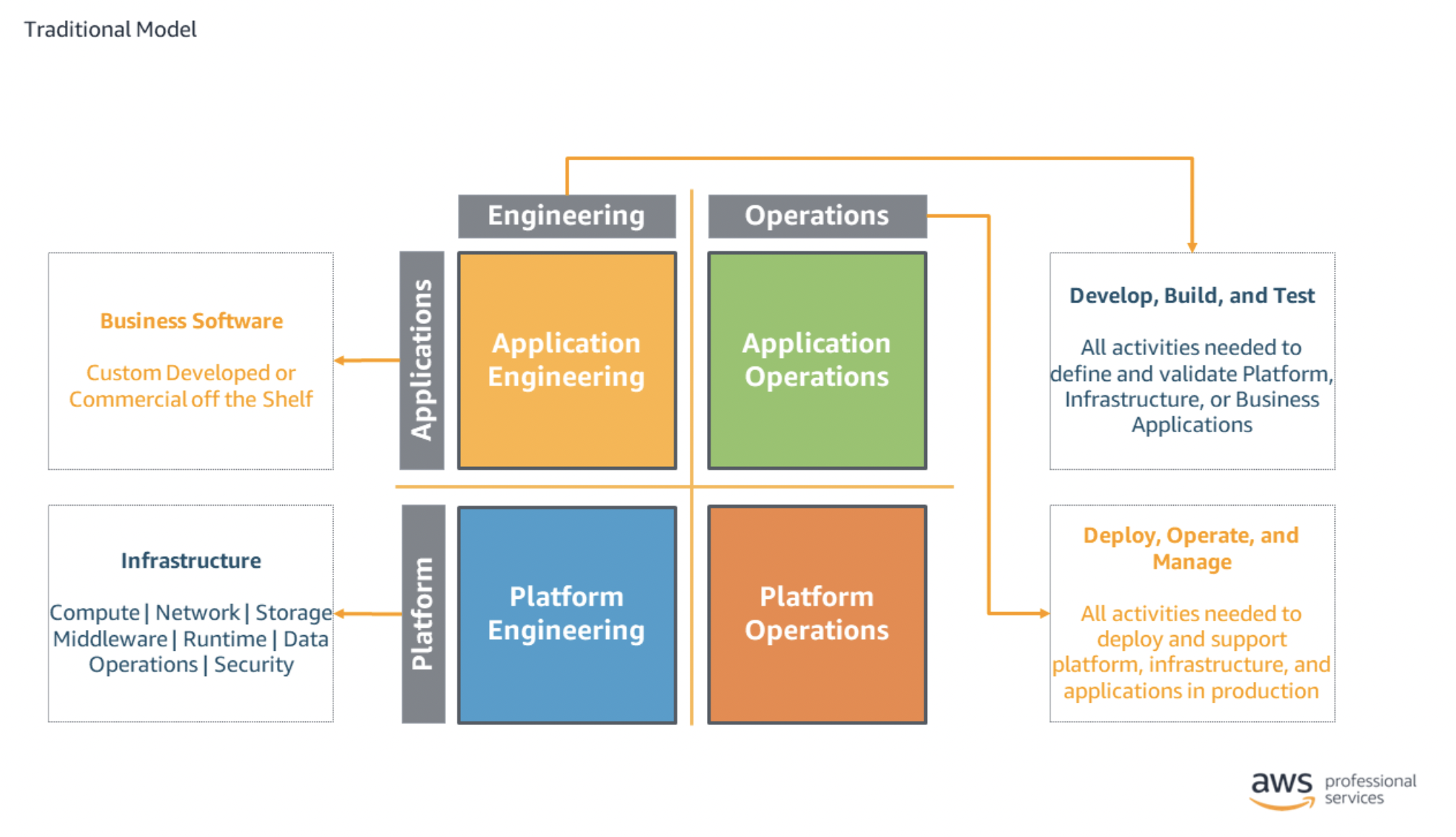 | In the fully separated model, each task in each quadrant is performed independently. PRO
CON
|
| Separated AEO and IEO with Centralized Governance | 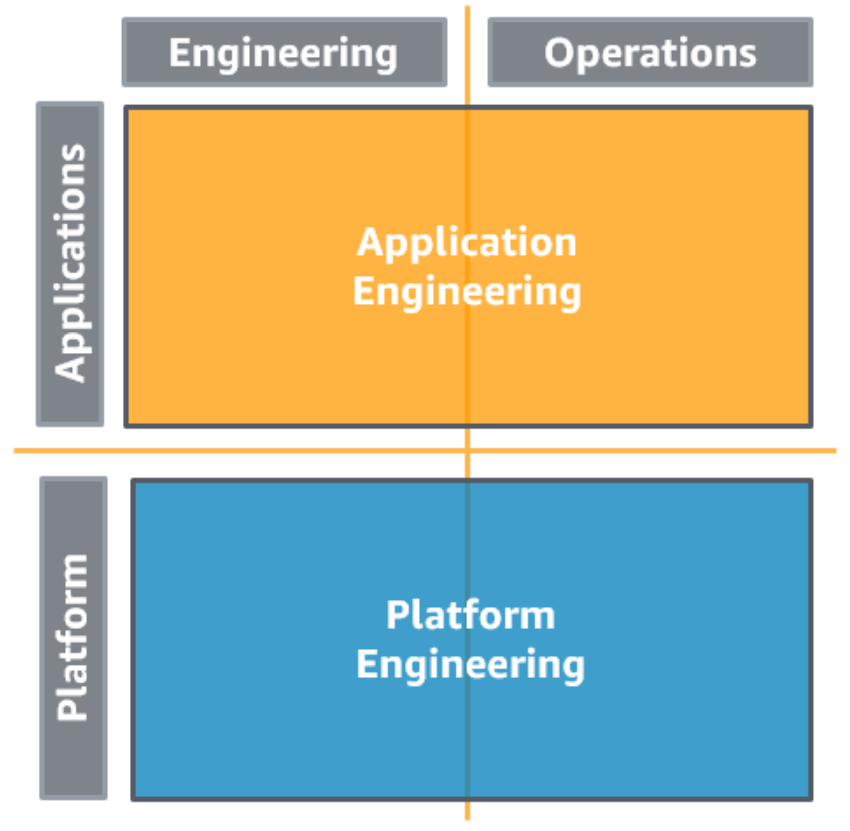 | Here we follow the "you build it, you run it" methodology. The engineers are responsible for the engineering and operation of their workload. To organize the teams, you should use AWS Organizations and AWS Control Tower. The platform engineering team provides a standardized set of services (e.g. development or monitoring tools) and access to cloud services to the application team. The AWS Service Catalog can be used to govern the tooling. PRO
CON
|
| Separated AEO and IEO with CG and a Service Provider | | Similar to the centralized governance, but you offload some operations tasks such a patching and updating to Managed Services. These service is handled by AWS and they take care of these tasks PRO
CON
|
| Separated AEO and IEO with CG and an Internal Service Provider Consulting Partner | | This model also establishes the "you build it, you run it" methodology. But the difference to the previous model, this enables a Cloud Operations and Platform Enablement (COPE) team which supports when there are no cloud related topics. It provides a forum to ask questions, discuss needs, and identify solutions. The platform engineering team builds the core shared platform capabilities governance via the AWS Service Catalog. PRO
CON
|
| Separated AEO and IEO with Decentralized Governance | | In this model the application engineers and developers perform both platform and application for engineering and operational workloads. Standards are still distributed by the platform team but the application teams are more free to engineer and operate their own capabilities in support of their workload. PRO
CON
|
Furthermore, it is worth noting that Resources, Processes and procedures, and operations activities have identified owners. Each team member should also know what they are responsible for. The responsibility between teams are predefined and negotiated.
Prepare
Attaining operational excellence operational excellence requires your understanding of your workloads and their expected functionality.
Design Telemetry
You should implement monitoring of your workload in order to see the health and internal state of your workload, identify when outcomes are at risk, and enable effective responses.
AWS provides their service AWS Cloudwatch to centralize and structure logs of the application.
AWS Cloudwatch also allows you to create alarms and metrics.
Use AWS X-Ray for collecting and recording traces as transactions travel through your workload. AWS X-Ray generates maps to see how the transactions flow across your workload and services in real time. But there are many third-party tools such as Datadog, New Relic, and Splunk which do these jobs very well. Talk to us; we also have expertise in these tools 😉Design for Operations
You should implement your entire workload as code. The benefit is that you can apply the same engineering discipline that you use for application code to your infrastructure. Use version control system like AWS Codecommit to enable tracking of changes and releases, and use AWS Cloudformation for your infrastructure templates.
It is recommendable to test and validate changes to help limit and detect error quicker. We at kreuzwerker often use Terraform and CDK 🤘
This pillar emphasizes automation to its max and you can put these processes in a CI/CD- pipeline. AWS comes with its own developer tool suits consisting of AWS CodeBuild for building and testing your code (Continuous Integration), AWS CodeDeploy for automating your code deployments (Continuous Deployment), AWS CodePipeline for automating and orchestrating the releases of the previous services. Are you using a different CI/CD- tool? Cool, we are too 😁 We have expertise in Gitlab, Jenkins, and Github Actions.
Try to make frequent, small, reversible changes to reduce the scope and impact of changes. Furthermore, you get feedback faster. Also, create multiple environments to experiment, develop, test before you deploy to your production environment. Below you will find a sample CI/CD pipeline, which we internally discussed during one of our CoP.

Perform patch management regularly to stay compliant. AWS Systems Manager Patch Manager and AWS Systems Manager Maintenance Windows are the services to automate your patch management workflow. When updating your images, you should manage those with EC2 Image Builder for you machine images (AMI) or push container images in Amazon Elastic Container Registry. It is important to share these design standard and best practices with your team. Create awareness amongst them via push notifications.
Speaking of best practices, AWS offers its program analysis based on Machine Learning Amazon CodeGuru for your pipeline to automatically identify potential code and security issues. It performs quality checks of your code and gives recommendations.
Mitigate Deployment Risks
You need to plan to revert to a known good state when unsuccessful changes happen. In a CI/CD pipeline, it stops when test and validation of changes fails. Also, use configuration management systems to track and implement changes. This reduces errors caused by manual processes and reduces the effort to deploy changes. AWS Config and its Rules helps to automatically monitor your AWS resource configurations across accounts and regions.Operational Readiness and Change Management
Before putting your workload into production, you should have a checklist. This checklist should include your personnel capabilities. Here it’s helpful to stay up-to-date via blogs, training and certifications and/or internal CoP.
Furthermore, review your AWS Config rules regularly and ensure consistency of them. Also test your CI/CD pipeline and add (manual) approval steps. Use metadata to identify your resources with tags and enable a tagging strategy for easy identification and findings with Resource Tags or Resource Groups. Also, prepare game days or “pre-mortems” to anticipate failure and create procedures where appropriate. This makes sure that your team gains confidence in case of outages or defects.
Operate
Understanding Workload Health
You and your team define, capture, and analyze workload metrics to measure the health of the workload such as error rate from the logs. Amazon Cloudwatch gives you workload insights. Your key performance indicators (KPIs) should be based on desired business outcomes (e.g. profit vs. operating expenses) and customer outcomes (e.g. customer satisfaction). Evaluate them regularly. Build dashboards with AWS Personal Health Dashboard or setup Amazon OpenSearch Service to monitor your workload. Let AWS alert you proactively when workload outcomes are at risk or anomalies are detected with Cloudwatch alarms and Cloudwatch Anomaly Detection.
Understanding Operational Health
You will want to use metrics based on operations outcomes to gain useful insights. Now you want to do analytics on your logs and use Cloudwatch Logs Insights or store the logs in Amazon S3, which then triggers an AWS Glue crawler to create an AWS Glue Data Catalog that then can be queried using Amazon Athena using standard SQL. The results can be visualized in Amazon Quicksight.
Responding to Events
Dr. Werner Vogels, CTO of AWS, said “Everything fails all the time.” You should be prepared and deliver consistent results when responding to alerts. Always perform a root cause analysis (RCA) after outage, and prevent recurrence of failures or document workarounds. Have a process per alert, ideally a runbook or playbook, with identified owner for any event for which you raise an alert. Prioritize operational events based on business impact and communicate directly with your users when the services they use are impacted. To respond to an event from a state change in your AWS resources, you should create a CloudWatch Events to send notifications to automate responses to events when for example a certain threshold is reached. Keep in mind that it is done better by third-party tools such as Datadog, New Relic or Splunk and investing in such a tool could prevent you from even more financial loss or even reputation.
Evolve
The last best practice area, Evolution, is the continuous cycle of improvement over time. In order to do that, you need to Learn, Share, and Improve.
Learn, Share, and Improve
This is quite simple, you want you and your team to learn from failures. Those lessons learned should be shared. Share them via performing post-incident analysis and ideally document them. Also, share these learnings across your organization or do it like Netflix or AWS and share them publicly. This will allow you to focus on delivering desired features.
Conclusion
Operational Excellence is crucial for business success and it is an iterative, as well as ongoing effort. Furthermore, it is a team effort and involves many team members from different units. Here are some key takeaways:
- Automate your workload
- Create a CI/CD- Pipeline which tests your code and deploys to a staging environment
- Perform operation as code and treat it as you would treat it in any software development project
- Monitor and Observe your workload
- Use logs in order to understand the health of your application
- Implement alerting on your defined metrics
- Let AWS Config monitor and govern configuration changes of your AWS resources
- Embrace the whole organization
- Train your team members to understand metrics and their roles
- Share lessons learned across the whole organization
- Perform post-incident analysis and document failures and outages
Take care and the final words are: we’re happy to perform an AWS Well-Architected Review with you.