

Cluster management and capacity planning. Loud and clear, the two pain points we keep hearing from clients during our Amazon OpenSearch assessments. I understand that: these concerns get in the way of the fun part, of building search and analytics experiences. The Amazon OpenSearch Service already saves a great deal of the hassle of managing the underlying clusters. However, you still have to make provisioning and operation decisions, such as how many data nodes, what instance types, when to upgrade, when and how to scale, and the like. And so we’re back at our pain points, cluster management and capacity planning.
Last week at AWS Re:Invent, Amazon announced something that could turn the table: Amazon OpenSearch Serverless. With OpenSearch Serverless, you spin-up search and analytics workloads without caring how they operate and only pay for the resources you consume. So, is that it? Is going serverless the ultimate solution to our clients’ pain points with OpenSearch? It depends™ Let’s see what changes, first.
From OpenSearch Domains to Collections
Amazon OpenSearch Service introduced domains to simplify the operation of an OpenSearch cluster, providing developers with a portfolio of EC2 instances already optimised for use as OpenSearch nodes, along with semi-automated mechanisms to scale, upgrade, and backup. Amazon OpenSearch Serverless goes a step further, removing the hardware from the picture and offering a higher abstraction level: collections. A collection is a group of indices representing a specific workload or use case, such as the application logs of your IT infrastructure or financial data backing your BI platform. It is the only thing you need to define to start using OpenSearch Serverless: no questions about nodes, instance types, sharding strategy, replicas, and scaling policies. Capacity is managed for you. Once you create a collection, you can query and index data using the same OpenSearch APIs as before (well, most of them) with minimum changes to your existing clients.
That’s all fun and games. But if you are anything like me, you want to know what’s happening behind the curtains. In a nutshell, every collection is backed by a minimum of four OpenSearch Compute Units or OCU: two OCUs for indexing data and two for searches. There are mainly two reasons for decoupling the flows: (i) use highly specialised instance types for each flow (think of node roles in Elasticsearch), and (ii) allow flows to scale independently and with no resource contention. You can currently scale to up to 20 OCUs per flow.
Another factor determining the OCUs setup is whether you specified your collections to hold time-series data - e.g., logs and metrics. If that is the case, OpenSearch Serverless will create a hot-warm architecture, where the freshest data will be persisted in OCUs with hot storage to optimise query response times. For collections without time-series data (called search collections), all OCUs will be instantiated as hot nodes.
Remaining on the storage topic, if, on the one hand, data nodes in Amazon OpenSearch Service use EBS volumes as the primary data storage, on the other hand, OCUs rely entirely on Amazon S3 - like the UltraWarm and Cold storage tiers of the non-serverless option. This is a testament to AWS’s improvements in performance for indexing and searching new data from S3, thanks to efficient caching solutions built-in in the OCUs.
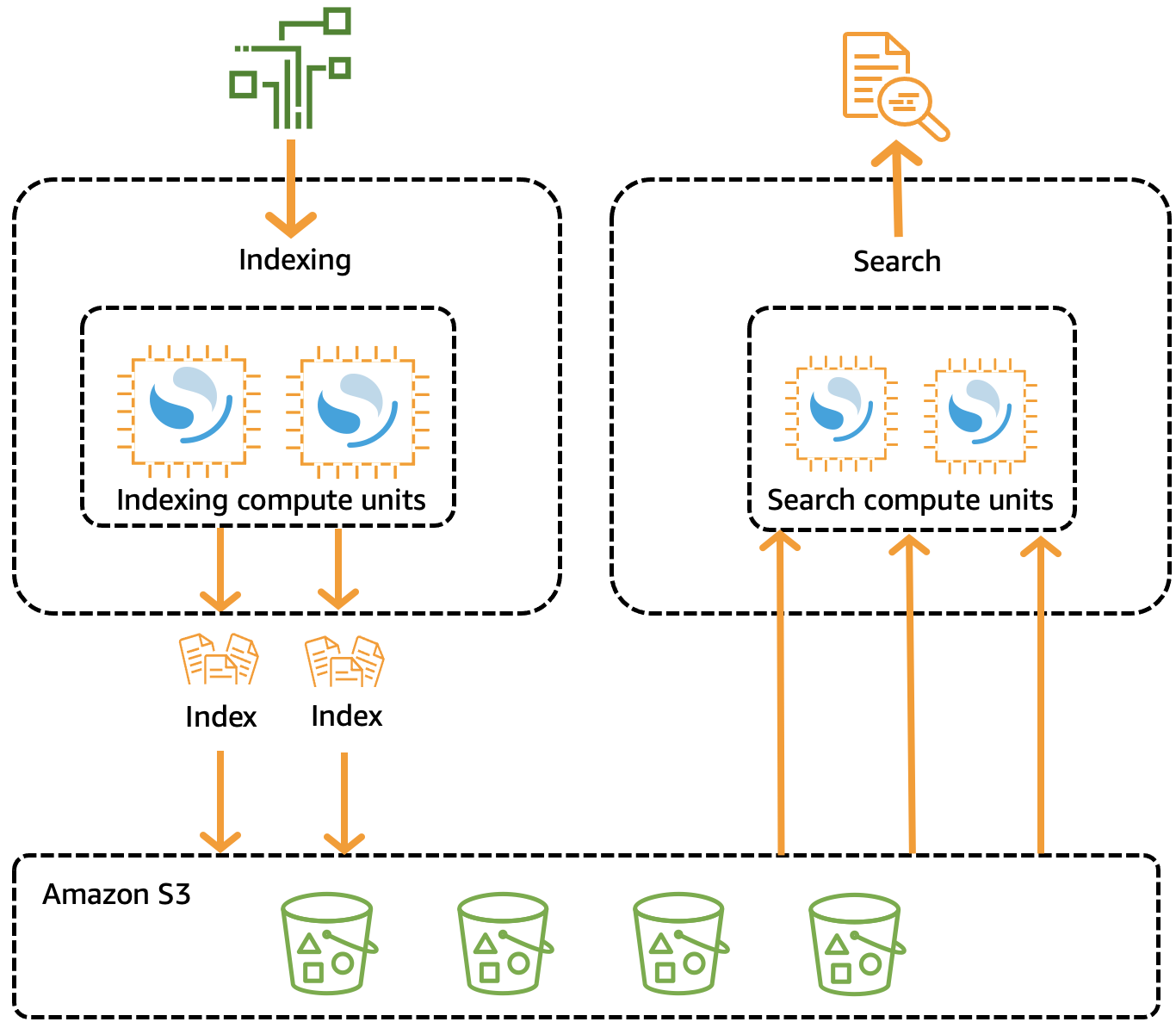
Amazon OpenSearch Serverless architecture. Source: docs.aws.amazon.com
A silver bullet for the OpenSearch Service pain points?
Get real: there is no such thing as a silver bullet. But, yes, OpenSearch Serverless does make it easier - and faster! - to enable petabyte-scale search and analytics workloads without the complexity of managing OpenSearch clusters, indices, and capacity. So let’s reassess the pain points mentioned at the beginning of this article.
Cluster management is entirely delegated to OpenSearch Serverless. It will provision the required resources, manage software patches and upgrades, provide redundancy to achieve high availability, and scale automatically to provide consistent performance based on demand (filling a significant gap with the Elastic world). This allows you to focus solely on your use cases (collections), modelling, searching, and aggregating your data. Of course, you still have the responsibility of securing your data, but - as for any AWS service - you get tons of tools to factor security in.
For capacity planning, OpenSearch Serverless is a game changer. Its ability to maintain consistent ingestion rates and search response times thanks to autoscaling and autotuning, makes upfront provisioning and demand forecasting no longer major concerns. Does this mean that you should forget about the efficiency of your workload? Of course not; that’s not cost-effective, nor is it sustainable. What it means is that capacity planning does not get in the way of quickly delivering your search and analytics products to market. Once live, you can continuously learn from their usage patterns and performance to fine-tune your models and queries. Or even switch back to OpenSearch Service, should that be more convenient for you. (Wait, OpenSearch Serverless as a capacity planning/performance benchmarking tool? Now, that’s something I’d like to explore more.)
Final thoughts
Amazon OpenSearch Serverless is the new serverless AWS kid in town, still in preview mode and only available in a few regions - for now. I’m excited about the opportunities it opens up, especially how it empowers developers and analysts to experiment with their data quickly, regardless of their level of technical understanding - that can come later. Also, it gave me some ideas (and another tool in my belt) to improve how I do standard capacity planning - I’ll write more on this. We all know Serverless comes with non-negligible costs and limitations, but, hey, I can’t lie: I can’t wait to experiment with Amazon OpenSearch Serverless and see how much value we can get out of it. I’ll keep you posted on how it goes.