


Verivox is an independent price comparison portal for products such as electricity, gas, DSL, mobile communications, loans and car insurance. Artificial intelligence is used to personalize advice and find the best rates for each customer. The company uses machine learning (ML) algorithms to do this.
The Problem
Because the algorithms had been programmed in R and ran on on-premises servers, the data science team made the decision to modernize their tech stack. First, the code base was switched to Python (the leading programming language in Data Science) and second, the ML models were made to run in AWS in the future.
The project was implemented by the Data Science team. The team had already rewritten some code in Python and gained experience with various AWS tools. After extensive research, the team finally settled on a combination of Amazon SageMaker, AWS Lambda, and the AWS Cloud Development Kit (CDK), which they had also already studied in detail.
Since the task required extensive knowledge of MLOps, data engineering and DevOps in addition to data science, Verivox decided to get support from kreuzwerker to ensure best practices and industry standards.
The Solution
kreuzwerker and Verivox worked together to put a previously selected, best practice based, ML model into production on AWS. This included, among other things, pre-tested ETL pipelines, as well as training, evaluating, deploying, and monitoring the ML model. The solution follows DevOps best practices and includes both CI/CD and Infrastructure as Code (IaC).
On the one hand, the code should act as a basis for future machine learning models, and on the other, be designed so that the project could be easily extended with additional models, without having to start each one from scratch again.
After analyzing the problem and the existing code, a serverless architecture that would allow AWS services to handle as many maintenance tasks as possible was chosen. Several small teams were formed, initially working independently on different topics. The kreuzwerker consultant worked with the various teams and gave them sufficient time to make progress independently or to familiarize themselves with the problems. In addition, new knowledge was shared in code reviews, daily meetings, and knowledge-sharing sessions. Over time, the teams’ work became more intertwined; by the end, each team member would be able to deploy the finished model and have a general understanding of all the solution’s components.
The Result
The ML model calculates the customers’ probability of getting a loan from different banks. The product should be an ML model that can be addressed via API and returns how high the probability is for a customer to be accepted by the bank.
The raw data for training the model is in a Snowflake data warehouse and should be pre-processed afterwards with Amazon SageMaker. With this processed data, several models will be trained, evaluated and the best one finally deployed. The models must be continuously monitored in live operation, both technically (Do the events arrive correctly? Is the prediction calculated fast enough?) and regarding the quality of the model. If a model does not deliver the desired results later, for example if the accuracy is too low, there should also be the possibility to go back to a previous model. Because of the necessary reproducibility and explainability of a model, it is necessary to store all data sets and encoders belonging to a model together with the model. All these features, up to the deployment of multiple endpoints and their management, are supported by SageMaker Pipeline, which is a CI/CD service for Machine Learning specifically developed by AWS.
In the later application, the user events are sent via Kong API to AWS Lambda functions, which pre-processes the events for the ML model. These continue to the SageMaker endpoint and then return with the probability calculated by the model. In the final step, they are then post-processed by the Lambda function and sent back to Kong API.
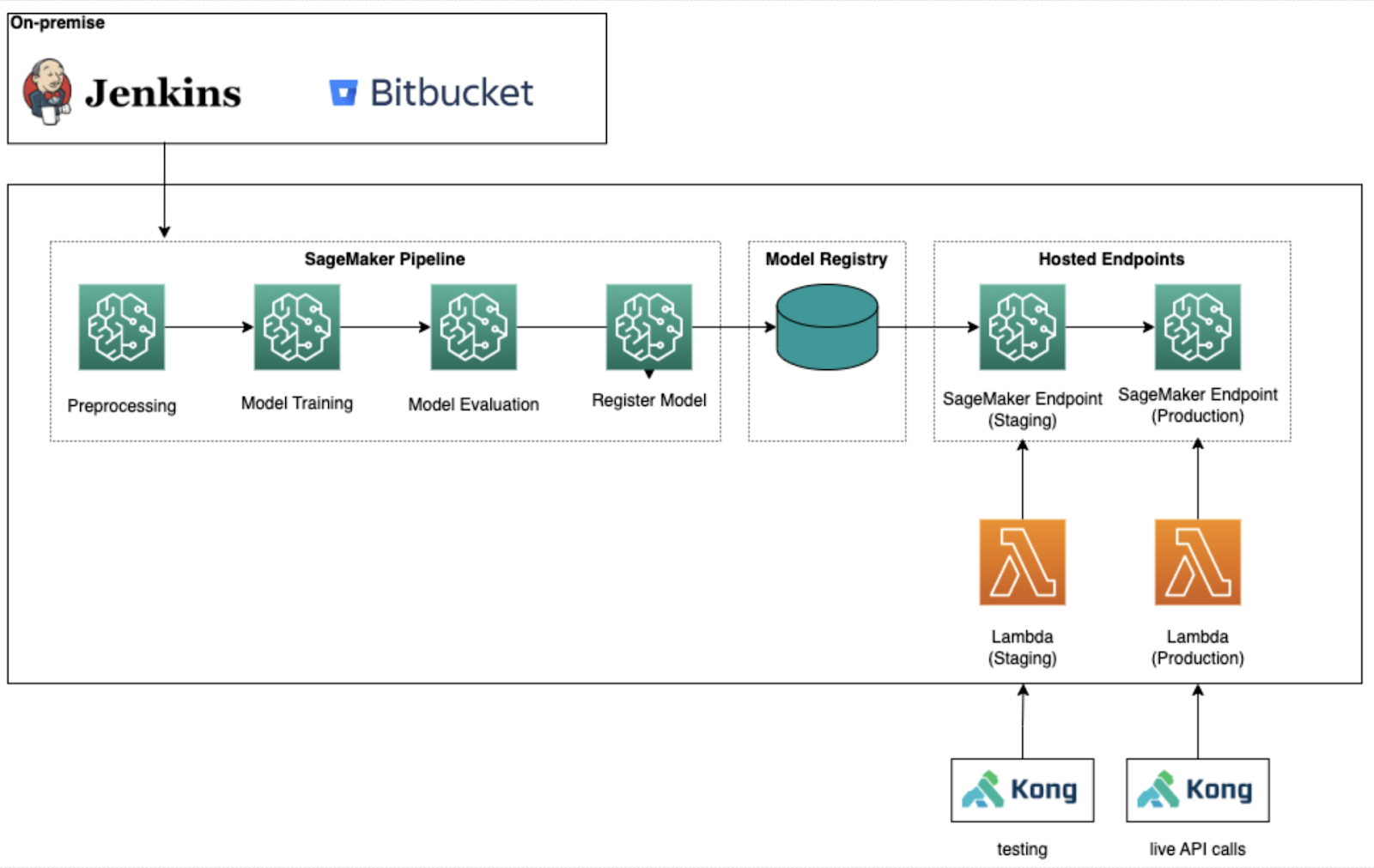
In order to make the solution easy to maintain, mainly serverless services were used that can scale independently and only incur costs when used.
Complete automation was another focus of this project. For this reason, a Jenkins CI/CD pipeline was developed to execute various linters and tests and finally deployed via the IaC framework AWS CDK. Deployments were triggered by Bitbucket, with infrastructure rolled out to different accounts depending on the branch. Finally, when merging into the master, the test environments were automatically cleaned up again.
Summary
Verivox and kreuzwerker implemented the solution in such a way that it can be easily extended to other ML models and many parts of the code, such as the CI/CD pipeline, and also cover future products without changes. Since the team at Verivox did all of their own coding, they are able to modernize the rest of their ML models and roll them out in AWS.
*“kreuzwerker enabled every single member of our team to reach their next skill level, creating impact that will long outlast the weeks they have worked with us.” *
- Elisabeth Günther, Verivox
In just a few weeks, Verivox, with the help of kreuzwerker, managed to put an ML model into production that follows both DevOps and MLOps best practices, is scalable, and whose performance can be monitored.